-
Dodiz

 .
.User deleted
Ciao per l'ennesima volta , nel corso di informatica è presente una piccola parte in assembly (nessuna versione in particolare, solo per dimostrare una probabile e superficiale traduzione dal c..) nella quale ho problemi a capire concettualmente come vengono gestite le funzioni.
premetto che ho letto questa discussione, capendoci ancora meno
Innanzitutto uno pseudo codice è così formato:CODICEX: RES 1
dove X è il nome della variabile a cui viene allocata 1 porzione di memoriaCODICESTART: READ X
start è l'etichetta per l'inizio del programma, come una funzione main, mentre read sarebbero funzioni di inputCODICEMOV #1, X
MOV indica un assegnamento, si assegna il valore 1 (se non ci fosse stato l'asterisco sarebbe stato il valore contenuto nella cella di indirizzo 1), in XCODICECICLO: BREQ X, FINE
ADD #-1, X
BR CICLO
BREQ è il salto condizionato, se X = 0, allora salta all'etichetta con segnato FINE
ADD ovviamente aggiunge un valore ad un altro, e BR è il salto incondizionato, ovvero ritorna all'etichetta CICLO in ogni caso..CODICEFINE: WRITE X
EXIT
END START
Codice per terminare (termina la prima l'etichetta START)
Oltre a questi operatori, si haCODICEJTS Etichetta
Jump to subroutine per saltare a una funzioneper il ritorno dalla funzioneCODICERTS
E gli operandi:Ri sono registri (con i numero del registro)CODICERi e (Ri)
la differenza è che se viene utilizzato Ri, l'operando è in Ri, mentre se viene utilizzato (Ri), l'operando è nella cella di indirizzo Ri, se viene utilizzato il primo, allora si utilizza il valore contenuto in X, per il secondo invece, l'operando è nella cella di indirizzo XCODICE#X e X
Il mio problema è capire la logica che viene utilizzata nelle subroutine..per esempio:CODICEint A, B, C;
int sum(int p1, int p2)
{int temp;
temp = p1+ p2;
return(temp);
}
void main ()
{
A=2; B=3;
C = sum(A,B);
}
Nello pseudo assembly con le istruzioni qui sopra, sarebbe:CODICEA: RES 1
B: RES 1
C: RES 1
STACK: RES1000 //riservo 1000 "celle" di memoria per lo stack
MOV #STACK, SP //SP è lo stack pointer, punta al primo elemento dello stack
ADD #999, SP //tratto lo STACK come pila, facendo puntare SP all'ultimo elemento dello stack
ADD #-1, SP //riservo l'ultimo elemento dello stack per il valore di ritorno
MOV A, (SP) //passaggio per parametri della funzione, "l'indirizzo" dello stack 998 contiene l'indirizzo di A
ADD #-1, SP //alloco un altro spazio di memoria per B
MOV B, (SP)
ADD #-1, SP
JTS SUM //passa ad eseguire la sub
l'istruzione JTS, inoltre, carica l'indirizzo della prossima istruzione da eseguire (quella dopo la fine della funzione che avrà etichetta RET:)
in pratica si avrà MOV #RET (SP);
SP scalerà ancora di 1 ADD #-1 SP;
e nel program counter (PC) la prossima istruzione da eseguire sarà SUM: MOV #SUM, PC
In questo momento lo STACK e' così formato:
|_______________| <-SP
|_____#RET____|
|_______B______|
|_______A______|
|_______________| (valore di ritorno, verrà inserito durante la funzione)
fin qui non ho avuto problemi..
Quando viene eseguita la funzione SUM, la prima cosa da fare è allocare uno spazio dello STACK per un registro R0, che verrà utilizzato come indirizzo fisso per le variabili locali..CODICESUM: MOV R0, (SP) //R0 è nell'indirizzo prima del valore di ritorno
ADD #-1 SP //prossimo valore
MOV SP, R0 //Il testo dice che viene caricato il valore di SP in R0, vuol dire che ora R0 punta all'elemento dove puntava SP? Non l'ho capito..
ADD #-1, SP //altro spazio di memoria per SP (la variabile TEMP)
MOV R0, R1 //R1 è ora l'indirizzo di riferimento, R1 dovrebbe puntare all'elemento prima di R0
ADD #4 R1 //R1 contiene l'indirizzo di A, come se R1 fosse temp e temp = A + B fosse scomposta in temp = A, e temp += B
MOV (R1) (R0) //Il valore di A viene inserito nella casella di indirizzo R0, che sarebbe quella dove R1 puntava?
vediamo la situazione dello stack a questo punto (se ho capito bene..)
|________________| <- SP
|_______A_______|
|_______R0______|
|_____#RET_____|
|_______B_______|
|________A______| <- R1
|________________|
dove R0 conteva l'indirizzo di R1, punta ad A (l'ultima A), sempre se ho capito bene
Ora la somma del secondo elemento:CODICEMOV R0, R1 //R1 ora punta alla prima cella di A
MOV #3, R1 //R1 ora punta a B
ADD (R1), (R0) //Il valore di B viene sommato alla cella di indirizzo contenuto in R0, cioè alla cella di A, giusto....?
MOV R0, R1 //R1 torna a puntare ad A + B
ADD #5 R1 //R1 ora punta al valore di ritorno
MOV (R0), (R1) //Il valore di R0 viene copiato nell'indirizzo di ritorno
ADD #2 SP //SP punta a R0 e i valori precedenti vengono "deallocati"
MOV (SP), R0 //che vuol dire? Che R0 punta a se stesso?
RTS //Aggiunge 1 A SP, facendolo puntare a #RET, e poi sposta l'indirizzo di RET nel Program Counter come prossima istruzione
Adesso ciò che succede (sempre nello start, dopo il ritorno)CODICERET: ADD #3 SP //"Deallocazione" di tutti i valori, ora SP punta al valore di ritorno
MOV (SP), C
EXIT
END START
Alcune istruzioni mi mandano in confusione..e a voi?
Le mie domande sono presenti nei commenti stessi..vorrei avere la conferma di aver capito bene la logica..
Edited by Dodiz - 16/2/2016, 17:49. -
+1 .
Stacco ora da lavoro, verso sera leggo bene e ti rispondo.  .
. -
+1 .
Riguardo allo Stack, dipende come lo stai rappresentando. Teoricamente non lo staresti rappresentando bene, in quanto lo stack cresce verso il basso e non verso l'alto (credo sia così in quasi tutte le architetture). Sulla base di questo credo cambi il modo in cui hai interpretato alcune parti del "codice" (in effetti è un autentico casino visto in questo modo).
ATTENZIONE: la sintassi è mov destinazione, sorgente, quindi banalmente se vedimov bp, sp, significabp = sp.
Perdonami, però mi esce più semplice spiegartelo con situazioni reali. Inizio con una breve spiegazione, così da chiarire i concetti fondamentali.
In moltissime architetture lo stack cresce verso il basso. Ciò significa che come nel tuo caso ci sarà un registro che punta in cima, su un indirizzo più basso.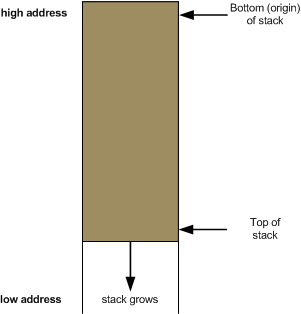
Nell'architettura x86 di Intel ci sono pochi registri da ricordare:SSrappresenta la base dello stack, o per meglio dire, il segmento dello stack (negli esempi non lo utilizzerò, è implicita la sua presenza)SPrappresenta il puntatore nello stack; per intenderci, è quello che nella figura si chiama "Top of stack" (corrisponde in pratica al tuo SP);BPquesto è l'indirizzo base, viene utilizzato dal programmatore per accedere allo stack (al posto di manipolare SP);IPnon ha nulla ache fare con lo stack, ma è un puntatore anch'esso (Instruction Pointer); come dice il nome, punta all'istruzione da eseguire (nel tuo caso è il program counter, PC)
Queste sono le informazioni base.
Nell'architettura di Intel, il programmatore può aggiungere o rimuovere dati dallo stack utilizzando le istruzioni PUSH e POP.
Detto ciò, considera questa semplicissima situazione in linguaggio C:CODICEint somma() {
return 0;
}
int main() {
int n = somma();
return 0;
}
L'aspetto importante, è cosa accade quando avviene la chiamata a somma()?
In asm, la chiamata avviene nel seguente modo:CODICEcall funzione
Quando avviene una chiamata come in questo caso, la CPU effettua il push del registro IP sullo stack, e come seconda cosa assegna al registro IP un nuovo valore: quello della funzione (il suo indirizzo).
Fatto questo, l'esecuzione inizia da quel punto (e la subroutine viene eseguita).
Supponiamo quindi che l'inizio dello stack (l'indirizzo più alto) sia 100 (decimale, è più comodo). Quindi SP = 100.
Nel momento della CALL avviene il PUSH (implicito, nel senso che non è controllato dal programmatore) del valore di IP per non perdere l'istruzione successiva da eseguire.CODICE[SP] = IP // 100
ora avremo SP = 99. La PUSH fa di fatto questo, che è ciò che nel tuo codice continua a comparire: esegue una sottrazione in pratica, decrementando SP. Nella pratica rispecchierà la dimensione del dato (se l'architettura è a 32bit, il decremento avverrà di 32bit, o se preferisci 4byte).
Sino a qui spero sia chiaro.
Quando passi dei parametri, i valori devono essere inseriti sullo stack prima della chiamata alla funzione. In C la situazione ora è la seguente:CODICEint somma(int a, int b) {
return 0;
}
int main() {
int a = 1, b = 1;
int n = somma(a, b);
return 0;
}
In asm possiamo scrivere la parte del main() come:CODICEpush b
push a
call somma
In questo caso ci sono 2 PUSH subito. Quindi se iniziamo da SP=100, dopo alla prima PUSH avremo SP=99 e dopo la seconda SP=98. La CALL provoca un altro decremento del valore, e quindi SP=97 (perchè viene inserito il registro IP).
Questa è la parte facile.
Ho parlato inizialmente del registroBP. Questo registro è quello che tecnicamente controlla lo stack frame. Quando chiami una procedura hai un frame; BP punta praticamente li, e viene utilizzato per accedere allo stack (in maniera sicura).
Se hai letto l'altro topic, avrai notato che la procedura inizia con quello che viene definito prologo:CODICEpush bp
mov bp, sp
Il push avviene in quanto (solitamente, come dice anche Intel lol) BP punta all'indirizzo di ritorno. Quindi quella PUSH preserva il valore. La situazione dello stack, eseguita quindi anche quella PUSH di BP è la seguente:CODICE100: b
099: a
098: [valore di IP]
097: [valore di BP]
SP => 0097
Giunti a questo punto, il codice prosegue conmov bp, sp; ora possiamo accedere allo stack tramite BP. Visto che lo stack cresce verso il basso ed inizia da indirizzi più alti, per "andare sopra" e prendere i parametri "pushati", dobbiamo incrementare di un certo numero BP.
Il certo numero in questo caso è [BP+2] per prelevare il valore di 'a' e [BP+3] per prelevare il valore di 'b'.
NOTA:
In una situazione reale su 32bit i valori non saranno esattametne questi, in quanto i dati sono di 4byte e non di 1 (come nell'esempio sopra). Quindi avremo:CODICE100: b
096: a
092: [valore di IP]
088: [valore di BP]
e di conseguenza, il primo parametro della funzione sarà a [BP+8] ed il secondo a [BP+12].
Nel caso del topic che hai letto inizialmente, i dati sono a 16bit, quindi solo 2 byte... e di conseguenza, l'accesso sarà diverso rispetto al caso mostrato ora: avrai [BP+4] e [BP+6].
Spero che sino a qui sia tutto chiaro ora - perdona le continue disgressioni, però preferisco essere preciso per non fornirti informazioni fuorvianti.
Bene, a questo punto, c'è un altro aspetto che non sapevo se toccare... i parametri locali, o meglio, quelle che si chiamano semplicemente "variabili locali della funzione" (o con nomi analoghi).
Ragiona sullo stack che vedi nel penultimo CODE: se lo stack cresce verso il basso, vuol dire per logica che la parte sopra è piena, e quella sotto è vuota... ed in effetti contiene i parametri della funzione; ergo non rimane che andare nella direzione opposta. Andare nella direzione opposta implica dover sottrarre qualcosa a BP.
In questo caso la situazione si complica un pochino:CODICEpush bp
mov bp, sp
sub sp,1
decrementando il valore di sp, riserviamo spazio per la variabile locale. L'accesso alla variabile locale avviene con [bp-1].
Ricorda sempre che con dati reali, si tratta di 16/32bit e non 1byte come in questo caso (ergo, se salvi un dato a 32bit, dovrai sottrarre 4 ad SP).
A questo punto, è il momento dell'epilogo:CODICEmov sp, bp
pop bp
ret
Preciso una cosa molto importante: arrivato a questo punto, è importante che lo stack sia stato manipolato correttamente e che sia coerente: questo significa banalmente che se nella funzione per qualche motivo hai fatto N push, prima del termine della funzione, dovrai fare N pop. In caso contrario la funzione non terminerà correttamente ed il risultato è imprevedibile... al 99.9% si verificherà un crash in quanto il dato non è un indirizzo valido, oppure non puoi accedervi.
Solitamente all'istruzioneretfa seguito il numero di byte da sottrarre per liberare lo stack. Una volta liberato tramite laret, viene fatto il push dell'indirizzo IP inserito inizialmente... e l'esecuzione riprende in pratica dalla riga successiva alla chiamata.
Spero perdonerai la mia spiegazione al posto di un commento passo-passo del tuo codice... e spero ti sia stata utile.
In caso di domande chiedi pure!. -
.
Dodiz se ti è stata utile la mia risposta ti chiederei di segnarla, così setto poi il topic come "Risolto". Se invece non è ancora risolto, ma hai altre domande, allora poni pure! .

|
